Generating test IDs
Automatically generate component unique test IDs for React
2019-11-19
TL;DR
An interesting approach to generating unique identifiers that can be used to target elements, during testing, in your React component render tree.
<p data-testid={testIDs.paragraph}>It Works!</p>
Preface
Because React Native does not have any concept of class names or ids, you use testID to find components in your render tree while testing. When I was working more in React Native, we would heavily use the testID prop in our tests to accurately target a component and test against it. Our testIDs were created manually while writing the component. In order for it to work properly, you have to make sure the testID is unique so you don't have collisions across components. So we had a naming convention for defining a testID. It went <class name>.<purpose>.<index if applicable>. If I were creating an Avatar component I might create Avatar.image. If the component was a row in a list, such as a list of assignments, we would create AssignmentRow.name.0. This way we could target a specific item in a row.
Problem
While working on a web project I wanted to bring this same paradigm over. My project does not use className for styling, opting rather for using the emotion css prop. So adding a bunch of className props to elements that serve no purpose other than for testing didn't feel right. I considered using the id attribute instead but ran into a few issues. The first being that I was adding another prop that was used for nothing but testing. The second was that the convention I had grown accustomed to in React Native would not work on the web when targeting elements using CSS selectors.
enzymeTree.find('#Avatar.name')
Spot the issue? Since the . is used in CSS to denote a class name this selector would not match an element with an id of Avatar.name since it would look for an element with an id of Avatar and a class name of name.
So rather I opted for using a data prop on the element.
<p data-testid='Avatar.name'>Name</p>
With enzyme, this can be targeted using find and an attribute selector.
enzymeTree.find('[data-testid="Avatar.name"]')
And because I don't want to have to write the attribute selector every time I want to find an element I can create my own find function specific to the data-testid attribute. Inside my jest setup file, I have
import ReactWrapper from 'enzyme/ReactWrapper'
ReactWrapper.prototype.findByTestID = function (testID) {
return this.find(`[data-testid="${testID}"]`)
}
So now when I want to find an element in a render tree with enzyme I can just call findByTestID with the test id, e.g. Avatar.name
So, problem solved.
Except...
This solution still has a downside I want to avoid. These test ids will be included in the rendered output of my application. They serve no purpose other than for testing and thus I don't want these test ids in production. I needed some way of conditionally applying these test ids. One solution might be to have a function that I can call with a test id that returns null in production and the test id in test. But this is a bit cumbersome. Another option would be to somehow auto-generate test ids and in production, it would always return null. I decided to pursue this route.
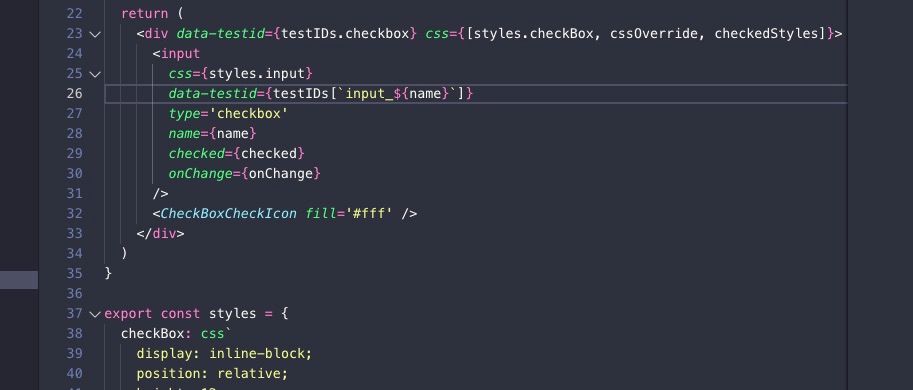
Ultimately the API I wanted was to be able to do something like data-testid={testIDs.image}. The testIDs object would be scoped to a specific component and thus any key of the object would be a unique identifier for this component only. In order to accomplish this kind of API, I used a feature of javascript called Proxy.
Proxy
A Proxy in javascript is an object that allows you to intercept get and set calls for all keys on the object. My proxy looks like
import uuid from 'uuid/v4'
export default function getTestIDs() {
if (process.env.NODE_ENV !== 'test') return {}
let ids = new Map()
let proxy = new Proxy({}, {
get: function(obj, prop) {
if (ids.has(prop) === false) {
ids.set(prop, uuid())
}
return ids.get(prop)
}
})
return proxy
}
In a component's file I will call getTestIDs() in order to get a testIDs object. This object is scoped to this file and thus won't conflict with any other component. I keep around a Map of all of the keys accessed off of testIDs in order to return the same unique identifier every time the key is accessed (testIDs.name === testIDs.name). This only happens in test, otherwise, an empty object is returned and all attempts to access a property on the object will be undefined and no data-testid attributes will show up in the rendered output.
So in practice, I would use this by doing
import getTestIDs from './getTestIDs'
export const testIDs = getTestIDs()
export default function MyComponent() {
return <p data-testid={testIDs.paragraph}>My paragraph</p>
}
Then in my test file, I can target that paragraph using the test ids.
import { mount } from 'enzyme'
import MyComponent, { testIDs } from '../MyComponent'
describe('MyComponent', () => {
it('renders', () => {
let tree = mount(<MyComponent />)
tree.findByTestID(testIDs.paragraph)
})
})
If I need to find an element that is in a component rendered by the component I'm testing I can import its test ids as a different name.
import { mount } from 'enzyme'
import MyComponent, { testIDs } from '../MyComponent'
import { testIDs as otherComponentTestIDs } from '../OtherComponent'
...
tree.findByTestID(otherComponentTestIDs.foobar)
If I am rendering a row of components where I need to target the nth row in the rendered output, I can create a key from test ids using some kind of index.
list.map((item, i) => <Row data-testid={testIDs[`row_${i}`]}>)
// In my test file then I can target that custom testID
tree.findByTestID(testIDs.row_0)
Drawback and workaround
One major drawback of this solution is in the findByTestID method. Enzyme's find methods are great for the fact that you can write a CSS selector which can include nested selectors such as div a (get all anchor tags in paragraph tags). But with findByTestID you can't do this. The workaround is then to just chain find calls.
tree.findByTestID(testIDs.paragraph).find('a')